はじめに
データ整形やETL処理という言葉を耳にしたことはあるものの、「実際にどうやってデータを加工するのか」「コーディングせずにETLを構築できるのか」といった疑問を持つ方も多いのではないでしょうか。
本記事では、数あるデータ統合サービスの中でもAWS Glueに焦点を当て、その中でもノーコードでデータ処理を実現できるAWS Glue DataBrewとAWS Glue Studioを取り上げます。
本記事では、DataBrew とStudioを組み合わせて、生データのクレンジングからETLパイプラインの構築・実行、そして出力結果の確認までを実施します。
この記事を通して、ノーコードでのETL処理に対する理解を深めていただければ幸いです。
1. 概要
1.1 背景
私自身がAWS Glueを使用したETL処理に触れる機会がありましたが、その際にDataBrewやStudioといったノーコード・ローコードツールの活用方法について詳細に解説された記事はなかなか見つけられませんでした。
同じように学習に苦労した経験を持つ方や、コーディング不要でETL処理を始めたい方もいるかもしれないと思い、自分自身でAWS Glue DataBrewとStudioを使用したハンズオンの内容を記事にしてみました。
1.2 目的
本記事の主な目的は、以下の2つです。
・AWS Glue DataBrewとStudioがETLのどの部分を担っているかを理解し、ノーコード・ローコードでのETL処理の全体像を掴むこと
・ハンズオンを通して、生データがビジュアルツールによってどのように変換・加工されるのかを理解すること
1.3 記事の概要
本記事は、前編と後編の2部構成となっています。
前編の内容:
・DataBrewとStudioの概要と特徴
・今回のハンズオンの概要
後編の内容:
・ハンズオンの内容紹介
・事前準備(S3バケット・IAMロール作成)からDataBrewとStudioを使用したETL処理の実行と結果の確認までの詳細手順
2. DataBrewとStudioの概要
2.1 AWS Glue DataBrew
2.1.1 概要
AWS Glue DataBrewは、ビジュアルデータ準備ツールです。
コーディング不要で、データの探索・クレンジング・正規化を行えるサービスで、直感的に操作できます。
AWS Glueにはコードベースの「Glue Job」と、ノーコードで扱える「DataBrew」があり、目的や利用者のスキルに応じて使い分ける必要があります。
以下では、Glue JobとGlue DataBrewを比較し、両サービスの適した利用場面を示します。
利用が適している場面:
| シナリオ | DataBrew | Glue Job |
| 新しいデータセットを受け取った際の初期探索や品質チェック | 〇 | 〇 |
| データ分析の前処理として、欠損値や異常値を確認・修正したい場合 | 〇 | 〇 |
| コーディングスキルを持たないユーザーがデータクレンジングを行う場合 | 〇 | ✕ |
| データ品質の問題を視覚的に把握し、チームで共有したい場合 | 〇 | ✕ |
凡例:
「◯」:該当サービスで対応可
「×」:該当サービスで非対応、または対応するが他サービス利用を推奨
2.1.2 主な特徴
- ノーコードのデータ準備
- GUIベースの操作画面
- 250種類以上の変換機能を提供
- クリック操作だけでデータクレンジングが可能
- 自動データプロファイリング
- データの統計情報を自動生成
- 欠損値、重複、異常値を視覚的に表示
- データ品質の問題を即座に検出
- インタラクティブなデータ探索
- データをリアルタイムでプレビュー
- 変換結果を即座に確認しながら作業
- カラムの分布やパターンをグラフで可視化
- レシピ機能
- データ変換手順を「レシピ」として保存
- 同じ処理を異なるデータセットに適用可能
- チーム内でクレンジング手順を共有・標準化
- データ品質ルール
- データ品質検証ルールを定義
- 自動的にデータ品質をチェック
- 品質基準を満たさないデータを検出
2.1.3 DataBrewが得意な処理
- 欠損値の補完・削除
- データ型の変換
- 重複レコードの除去
- 異常値の検出と処理
- 文字列の正規化(トリミング、大文字小文字変換)
- 日付フォーマットの統一
- カラムの追加・削除・リネーム
2.2 AWS Glue Studio
2.2.1 概要
AWS Glue Studioは、ビジュアルETLパイプライン構築ツールです。
ドラッグ&ドロップの操作で、データの抽出(Extract)・変換(Transform)・ロード(Load)の一連のワークフローを設計できます。
Apache Sparkベースで大規模データ処理に対応しています。
AWS Glueにはコードベースの「Glue Job」と、ノーコードで扱える「Studio」があり、目的や利用者のスキルに応じて使い分ける必要があります。
以下では、Glue JobとGlue Studioを比較し、両サービスの適した利用場面を示します。
利用が適している場面:
| シナリオ | Glue Studio | Glue Job |
| 複数のデータソース(S3、RDS、Redshiftなど)をビジュアルに統合して本番ETLを設計・運用したい | 〇 | ✕ |
| コード中心(PySpark/Scala)で複雑なロジックや外部ライブラリを活用したETLを実装したい | ✕ | 〇 |
| 定期/イベント駆動のバッチパイプラインをGUIで素早く構築・変更したい | 〇 | ✕ |
| Parquet出力・パーティション分割・Glue Data Catalog連携を視覚的に設定したい | 〇 | ✕ |
| 出力レイアウトやパーティション設計をコードで高度に制御したい | ✕ | 〇 |
凡例:
「◯」:該当サービスで対応可
「×」:該当サービスで非対応、または対応するが他サービス利用を推奨
2.2.2 主な特徴
- ビジュアルETL開発
- ノードベースのグラフィカルインターフェース
- ドラッグ&ドロップでETLワークフローを構築
- データフローを視覚的に把握しやすい
- 豊富な変換ノード
- Data Source: S3, RDS, Redshift, JDBC など
- Transform: Join, Filter, Aggregate, SQL Query, Change Schema など
- Data Target: S3, Redshift, データカタログ など
- カスタム変換(PySpark/Scalaコード)も追加可能
- スケーラビリティ
- Apache Spark基盤で並列分散処理
- テラバイト級のデータを効率的に処理
- DPU(Data Processing Unit)で処理能力を調整
- ジョブの実行管理
- オンデマンド実行
- スケジュール実行(cron式で定期実行)
- トリガーベース実行(イベント駆動)
- ジョブの実行履歴とモニタリング
- コード生成機能
- ビジュアル設計からPySparkコードを自動生成
- 生成されたコードを確認・編集可能
- 既存のGlue Jobコードとの統合が容易
2.2.3 Studioが得意な処理
- 複数データソースの結合(Join)
- データの集計・グループ化(Aggregate)
- 複雑な条件によるフィルタリング
- データ型の一括変換
- パーティション分割した出力
- 大規模データの並列処理
- 定期的なバッチETL処理
3. ハンズオンの概要
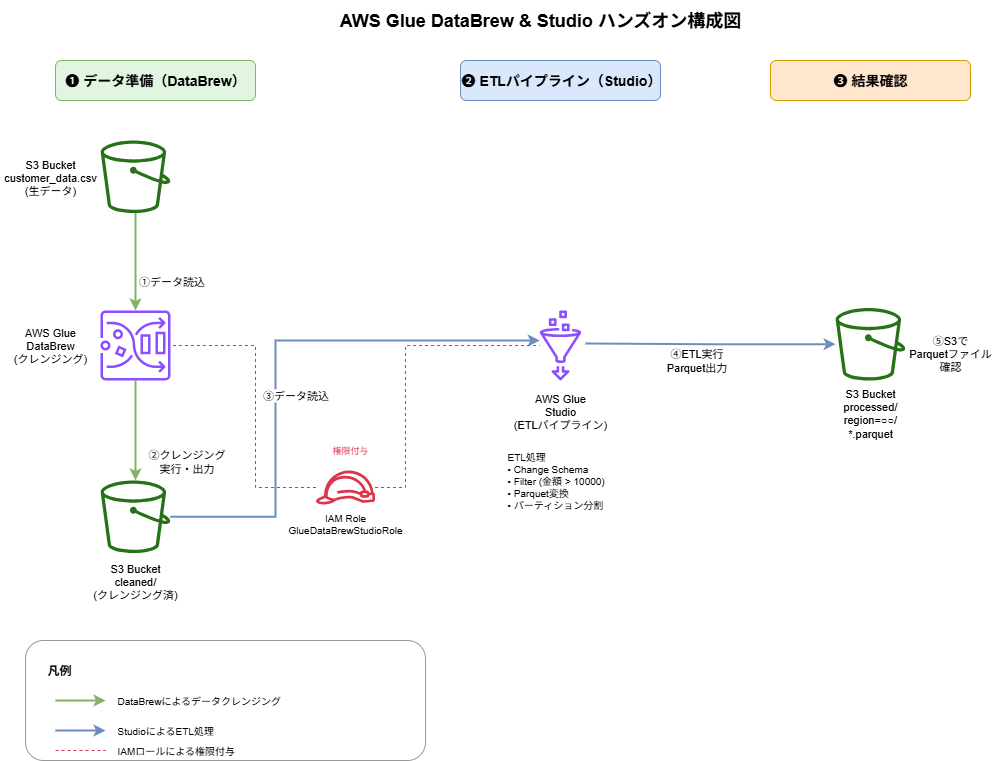
本ハンズオンでは、AWS Glue DataBrewとStudioを組み合わせて、実際のデータ処理ワークフローを実施します。
具体的には、顧客の購入履歴データを題材に、以下の一連の流れを実践します:
- DataBrewによるデータクレンジング
- 生データの品質問題(欠損値、データ型の不整合)を視覚的に確認
- GUIを使用して欠損値の補完やデータ型の修正を実施
- クレンジングレシピを作成して処理を自動化
- StudioによるビジュアルETLパイプライン構築
- クレンジング済みデータを読み込み
- ドラッグ&ドロップでデータ変換フローを設計
- 高額購入顧客への絞り込みとデータ型変換を実施
- 地域別にパーティション分割してParquet形式で出力
- 結果確認
- S3に出力されたParquetファイルの確認
4. まとめ
本記事の前編では、AWS Glue DataBrewとStudioの概要と特徴、ハンズオンの概要について解説しました。
後編の記事では実際にAWS Glue DataBrewとStudioを動かしてノーコードでETL処理を実施していきます。
後編はこちら:[AWS Glue DataBrewとStudioを使用しノーコードでETL処理の構築【後編】