Pythonでサーバーレスデータ処理 ~Pandas + Lambda + S3活用~
本記事では、データ分析においてデータエンジニアが主に実施するデータの前処理について、
Pythonのデータ処理ライブラリである「Pandas」を用いた手法を紹介します。
対象データとなるCSVファイルをS3に格納し、AWS Lambdaから対象データを直接読み込み、前処理を行います。
また、前処理後のS3データをQuickSightに取込む際のプロセスも紹介します。
本記事の概要
データ分析の過程では、データ収集後に目的の格納先(データベース、データウェアハウス、BIツール、ストレージ等)に向けて、
データを取込む作業(Loadする作業)が発生します。
このデータ取込みに関し、ストレージであれば特にデータ形式を考慮する必要はございませんが、
例えば、データウェアハウスへの取込みでは、事前に構造化データ/半構造化データにデータの持ち方を修正する(前処理する)必要があります。
また、データ内において将来的に活用しないことが明らかな不要な情報を取り除くこともあります。
こちらの記事では、BIツールであるAWS QuickSightへの取込みデータにおいて、データ前処理を手動で実施しております。
ただ、手動作業は下記の要因より非効率であり作業品質が担保されません。
- 作業時のヒューマンエラー(作業者によって品質のばらつきが発生する。)
- 作業の属人化(何をどう実施したか作業者しか分からない。)
- 大量の同一ファイルに対して非効率(作業スピードが遅い。)
- データ構造変化に伴う拡張性の不足(既存マニュアル通りに進まない。)
上記を解決するために、本記事ではデータ操作に特化したPythonライブラリであるPandasを用いてデータ前処理を行います。
この処理をAWS Lambda上で実行し、AWS SDK(boto3)を介してS3から直接データ読込みと書込みを行います。
今回の対象データは上記の記事でも使用したオープンデータe-govポータルにおける2015年の人口動態データとなります。
⇒ 人口動態調査人口動態統計確定数人口年次
実施プロセス
実施プロセスとして、下記を行います。
作業前提として、aws cliがインストールされており、格納先のS3バケットが作成されている必要があります。
- ローカル環境からS3バケットへのファイルアップロード(AWS CLI経由)
- Lambda初回起動と事前設定
- Lambda初回起動
- LambdaにS3バケットへのアクセスのために、IAMロール設定
- レイヤ追加
- データ読込
- 前処理実施
- QuickSightへの取込み
1. ローカル環境からS3バケットへのファイルアップロード(AWS CLI)
AWS CLIを使用して、ローカル環境からS3バケットに該当ファイルをアップロードします。
- 事前にローカル環境の適当なフォルダに対象データを格納します。
aws s3 lsコマンドを用いて、事前に対象ファイルがS3バケットに存在しないことを確認します。aws s3 ls s3://{バケット名} --profile {プロファイル名}
・上記は同じ環境から複数AWSアカウントへのアクセスを使い分けるために--profileのオプションを指定しています。
アクセス先のAWSアカウントが1つであれば指定は不要です。
この時は最初に設定したアクセスキー/シークレットアクセスキーを用いてアクセスされます。
・プロファイルを指定する場合は、下記を設定します。
1. ./aws/config内にCLI実行時のプロファイルの設定
⇒ スイッチロールする場合は、ロールARNをプロファイルに記載すること。
2. ./aws/credentials内にIAMユーザのアクセスキー/シークレットアクセスキーの設定
3. プロファイル設定後は、aws configure list-profilesコマンドより設定結果を確認できます。
aws s3 cpコマンドを用いて、対象ファイルをS3にアップロードします。
⇒aws s3 cp {ローカルファイルパス} s3://{バケット名} --profile {プロファイル名}- 再度、
aws s3 lsコマンドで対象ファイルがアップロードされていることを確認します。
⇒aws s3 ls s3://{バケット名} --profile {プロファイル名}
上記よりS3にファイルをアップロードすることができました。
2. Lambda初回起動と事前設定
以降よりLambdaの作成と設定を行います。
Lambda初回起動
早速、Lambdaを作成します。
AWSマネジメントコンソールより、Lamdda > 関数を作成、を選択します。関数の作成画面にて、一から作成を選択します。
S3へのオブジェクトアップロードを契機にLamda処理を開始するコードをデフォルトコードとして選択することもできますが、
今回は新規で作成します。
他の設定は下記とします。
- お好きな関数名を入力
- ランタイムは、今回
Python 3.10を選択 - 他はデフォルト設定
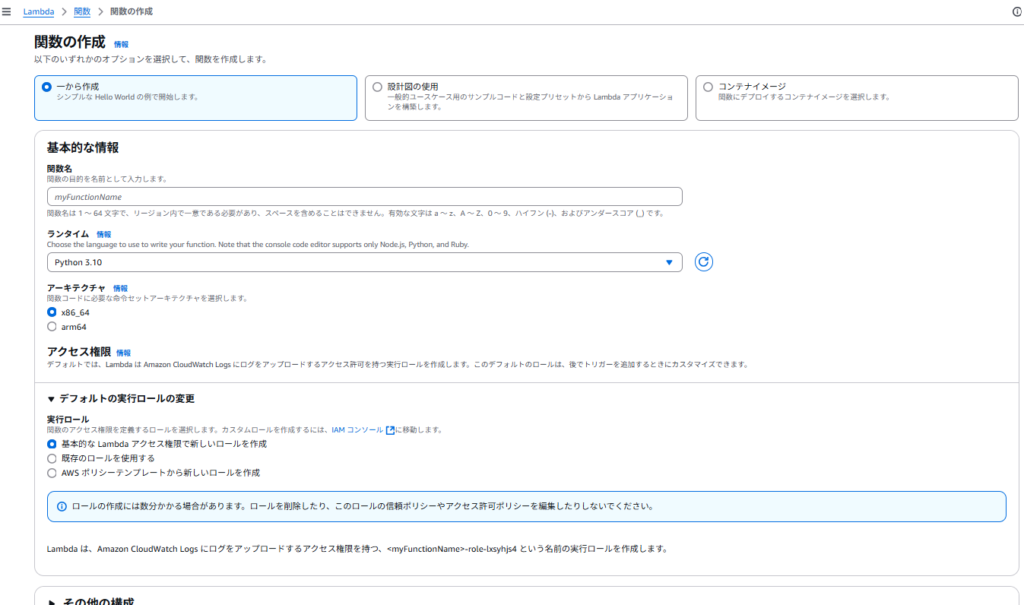
作成完了後、Lambdaの初回起動時の画面は下記となります。
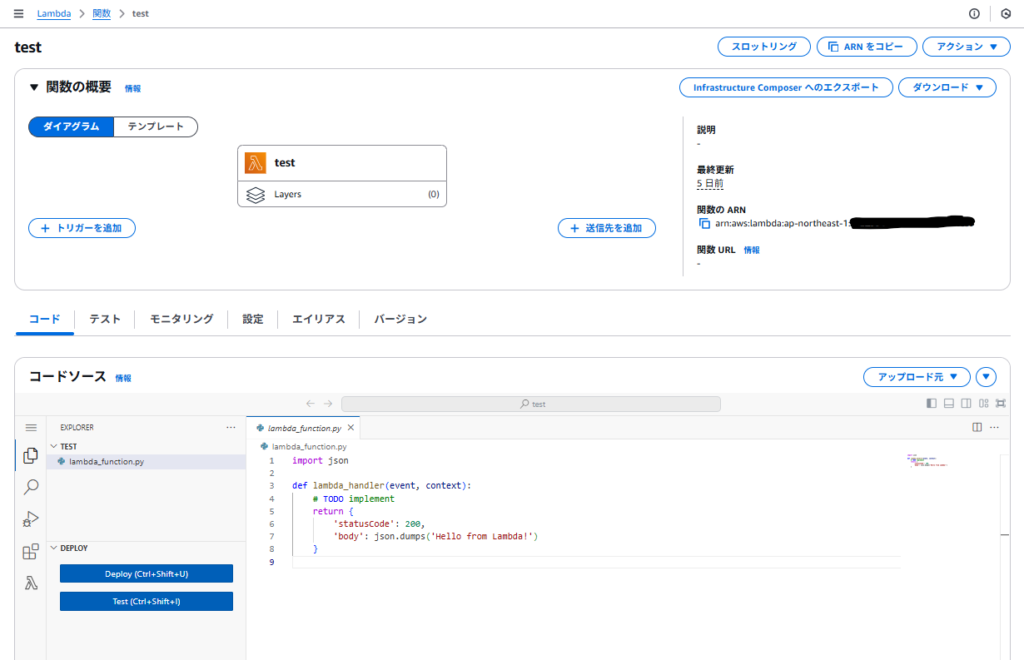
初回コードは下記となります。
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}上記のPythonコードに前処理の設定を追記していきます。
ここでは、lambda_handler関数の引数としてevent, contextが自動設定されてますが、今回はこの引数は使用しません。
LambdaにS3バケットへのアクセスのために、IAMロール設定
次にLambda実行ロールを設定します。
Lambda作成後、設定 > アクセス権限を見ると、自動で実行ロールが作成されています。
この実行ロールに今回使用するデータ格納先のS3バケットへの許可設定を行います。
セキュリティ面での制約が特になければ、List, Get, Put権限を付与すればよいと思います。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::{S3バケット名}",
"arn:aws:s3:::{S3バケット名}/*"
]
}
]
}レイヤーの追加
Lambdaレイヤーにライブラリを追加します。
レイヤーを用いてコードとは別にライブラリを管理することで、使用ライブラリのバージョン等を効率的に管理できるようになります。
追加するライブラリは、データ分析用のpandas、S3内のファイル操作用のfsspec, s3fsとなります。
PandasライブラリはAWSSDKPandas-Python310という名前でAWSから公式に提供されているため、選択するだけでレイヤーに追加できます。
ただ、fsspec, s3fsはzip化してアップロードする必要があります。
ローカル環境でpip install fsspec s3fsコマンドを実行し、インストールされたファイルをzip化し、Lambdaレイヤーに追加します。
3. データ読込
ここでは大幅な改変を実施せずスモールスタートのために、まずはLambdaからS3にアクセスし、ファイルをリネームして再度アップロードする処理を行います。
対象ファイルがCSV形式のため、read_csv、to_csvメソッドを用いてファイルの読込みを行います。
import json
import urllib.parse
import boto3
import pandas as pd
from io import StringIO
# S3クライアント作成
s3_client = boto3.client('s3')
def lambda_handler(event, context):
bucket = '{S3バケット名}' # S3バケットを指定
key = '{対象ファイル名}' # S3キーを指定
next_token = None
print(f"Processing file: {key} from bucket: {bucket}")
# エラーハンドリング処理
try:
while True:
# バケット内のオブジェクトを一覧表示する。
## ページネーション機能を追加する。`next_token`が存在する限り、リスト実行を続ける。
if next_token:
s3_list_object = s3_client.list_objects_v2(
Bucket=bucket,
ContinuationToken=next_token,
)
else:
s3_list_object = s3_client.list_objects_v2(
Bucket=bucket,
)
if "Contents" in s3_list_object:
for obj in s3_list_object["Contents"]:
print(obj["Key"])
else:
print("該当バケット内にオブジェクトが存在しない。")
if s3_list_object.get("IsTruncated"): # キー`IsTruncated`から、リストオブジェクトが全て取得されたかどうかを判定する。
next_token = s3_list_object["NextContinuationToken"]
else:
break
s3_get_object_response = s3_client.get_object(Bucket=bucket, Key=key) # 呼出し済みS3クライアントで対象オブジェクトを取得
csv_data = s3_get_object_response['Body'].read().decode('shift-jis') # 対象オブジェクトにおけるBody内容を読込み、デコード処理
if not csv_data.strip():
raise ValueError("CSV file is empty or contains only whitespace")
# データフレーム化して前処理を実施
df = pd.read_csv(
StringIO(csv_data),
encoding = 'utf-8', # UTF-8でエンコード
)
'''
ここに前処理内容を追記する。
'''
# 出力先キー名を指定
output_s3_path = f's3://{bucket}/output_{key}'
# csv形式で出力
df.to_csv(
output_s3_path,
index = False,
encoding = 'utf-8', # UTF-8でエンコード
storage_options={'anon':False}, # S3内のオブジェクトにアクセスするために指定
)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise eコード作成後、Deployを実行します。Deployが成功しましたらテストイベントを作成し、テストを実行します。
テストイベントにおけるイベントJSON内容ですが、特に今回はLambdaに引数を渡さないため空欄でも問題ございません。
4. 前処理実施
次に、先ほど作成したコードに前処理のコードを追加します。
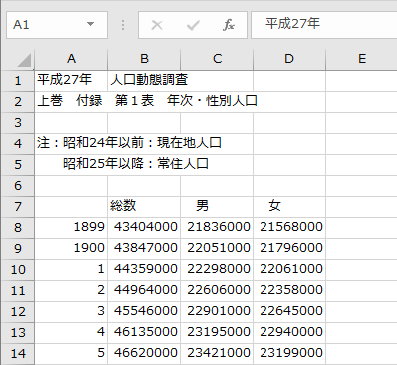
上記が対象データ(CSVファイル)の一部となります。この対象データに対して下記3点の変更を行います。
- 読込み対象カラム指定
- ヘッダ名の変更と、年次カラムのヘッダ名補完
- データの欠損値補完(
年次カラム内の千と百の位の補完)
コードを全て記載すると長くなるため、前出のコードからの変更箇所のみ記載します。
# ライブラリの追加
import sys
import fsspec
import s3fs
# 下記、年次の欠損を補完する関数を追加
def fix_year(value, prev_year=[None]):
value = value.strip() # 空白文字の削除
if value.isdigit() and len(value)==4: # 文字列が数字であり、4桁である場合、
prev_year[0] = value # 4桁(例. 1910)の数字をリストに格納
return value
elif value.isdigit() and len(value)==2: # 文字列が数字であり、2桁である場合、
return prev_year[0][:2] + value # 4桁(例. 1910)の先頭から2文字とvalueの文字を結合
else:
return value
# 前出の`データフレーム化して前処理を実施`箇所を下記に変更
df = pd.read_csv(
StringIO(csv_data),
skiprows=6, # カラム読込み開始行:7行目
nrows=123, # カラム読込み終了行:124行目
encoding='utf-8', # UTF-8でエンコード
)
# 前出の`ここに前処理内容を追記する。`箇所に下記を追加
## 既存のヘッダ名変更
df.columns = ['year', ' amount_of_population', 'men', 'women']
## dfの型を確認
print('変換前の型:', df.dtypes)
## 関数を用いて`year`データの欠損値補完
df['year'] = df['year'].apply(fix_year)
## `year`の型をintegerに変換し、dfの型を確認
df['year'] = df['year'].astype(int)
print('変換後の型:', df.dtypes)
# 前出の`csv形式で出力`箇所を下記に変更
df.to_csv(
output_s3_path,
index = False,
encoding = 'utf-8', # UTF-8でエンコード
storage_options={'anon':False}, # S3内のオブジェクトにアクセスするために指定
)当初、上記を実行すると、Lambdaのデフォルトタイムアウト(3秒)時間ではエラーが発生しました。
そのため、タイムアウト時間を30秒に変更しています。
上記を実行すると、処理後のデータがS3にアップロードされます。
Lambda内のログを確認すると、実行成功していることが分かります。
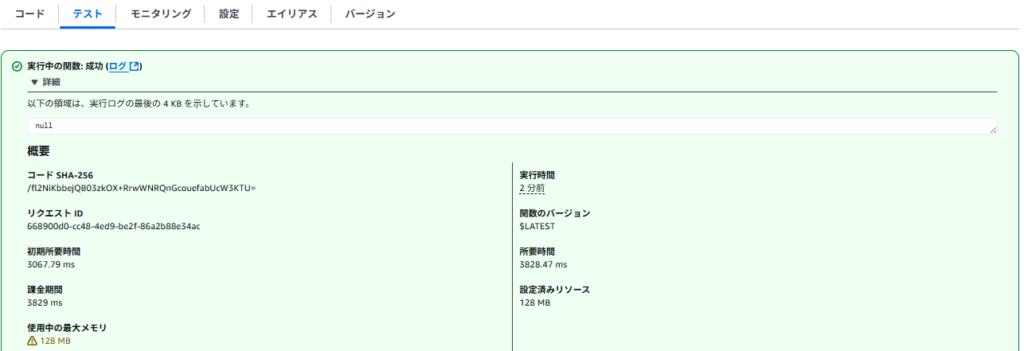
また、上記ログのリンク先に進むと、CloudWatchログに格納された結果も確認することができます。
S3にアップロードされたcsvファイルの中身も想定通りに変換されています。
5. Quicksightへの取込み
上記プロセスで前処理自体は完了となりますが、
ここではS3に保存した取込み用データをQuickSightに取込む際に必要なマニフェストファイルについて紹介します。
S3に保存した取込み用データをQuickSightに取込むためには、別途マニフェストファイル(JSON形式)を用意する必要があります。
今回は下記の内容にてマニフェストファイルを作成しました。
{
"fileLocations": [
{
"URIs": [
"https://{S3バケット名}.s3.ap-northeast-1.amazonaws.com/{対象データのファイル名}"
]
}
],
"globalUploadSettings": {
"format": "CSV",
"delimiter": ",",
"containsHeader": "true"
}
}[Amazon S3 のマニフェストファイルでサポートされている形式](https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/supported-manifest-file-format.html)
上記のJSONファイルをS3にアップロードします。
また、このまま接続検証を行うと、下記画像のようにアクセス拒否されるため、管理画面から該当S3バケットのアクセス許可を行います。
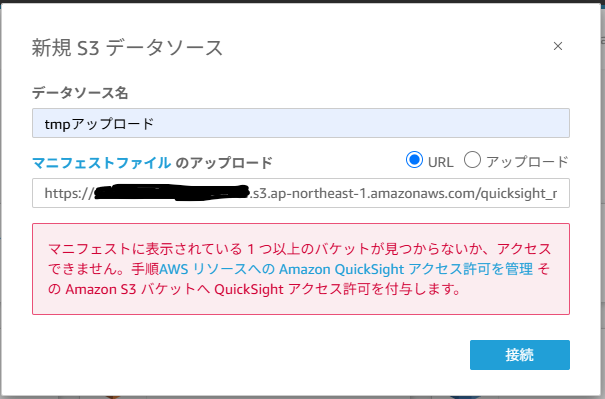
アクセス許可を行い、再度接続検証を行います。
先程のマニフェストファイルの中身が正しければ、アップロード手前の状態まで進めることができます。
こちらでQuickSightへの前処理後のデータ取込み準備が完了したことになります。
まとめ
今回はシンプルな前処理内容でしたが、どういった前処理を行うか、といった要件に従いコード部分を変更すれば今回サンプルとして使用したデータ以外においても利用することができます。
また、今回は変更しておりませんが要件次第ではLamdaのメモリを変更する必要がございます。
以上、AWS CLIよりローカル環境からS3へデータを格納し、
格納データに対して直接、Pythonライブラリである「Pandas」を用いて、
Lambda上でデータ前処理を実装、QuickSightでのデータ可視化準備まで行う手法の紹介でした。

