はじめに
本記事はAWS GlueでETL処理を実施するブログ記事の後編になります。
まだ前編を見られていない方は下記に前編のリンクを記載していますのでご確認下さい。
初めてでもできる!AWS GlueでETL処理を構築してみよう【前編】
今回の後編ではハンズオンの概要手順と詳細手順について解説しております。
初めての方でも取り組みやすいように、詳細手順では各プロセスのキャプチャも載せています。
1. 概要
1.1 前編
・ETL処理の基本的な概念と、AWS Glueの各サービスがそれぞれETLのどの部分を担うのかを解説
・ハンズオンの概要について解説
1.2 後編
・ハンズオンの流れを概要手順で解説
・事前準備とETL処理の実行から結果の確認までを行う詳細手順を解説
2. ハンズオン概要手順
本ハンズオンは、以下の手順で進めます。詳細な手順は次の章で解説します。
準備・設定
・データ準備: 生データとS3バケットを作成し、該当のバケットにアップロードを行う
・IAMロールとポリシーの作成: ETL処理に必要な権限設定を行うExtract(抽出)
・生データのメタデータ抽出: Glue Crawlerを実行し、S3にアップロードした生データのスキーマ情報を自動的に取得Transform(変換)
・データの加工: Glue Jobを作成・実行し、生データから加工済みのデータを生成Load(ロード)
・データの書き込み: Transformフェーズで加工されたデータが、S3バケットに書き込まれる出力確認
・結果の確認: S3バケットの該当フォルダに、変換・加工されたデータが正しく出力されているかを確認
・加工済みデータの抽出: Glue Crawlerを実行し、S3にアップロードされた加工済みデータのスキーマ情報を自動的に取得
・Glue Data Catalogの確認: Glue Crawler実行によって作成されたData Catalogの該当テーブルを確認
3. ハンズオン詳細手順
ここから実際にハンズオンを実施する為の詳細な手順を解説します。
3.0 環境準備
- 用意するデータの作成
今回、生データとして取り扱う対象データは、5行5列のシンプルな販売履歴CSVファイルです。
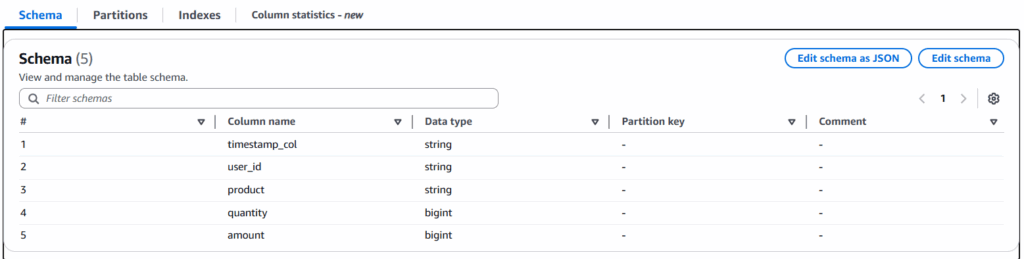
具体的には、購入日時を示すtimestamp_col購入者のuser_id購入されたproductquantityamountといった項目を含んでいます。
このデータは、ユーザーの購入履歴を記録しています。
下記のデータをraw_data.csvという名前で保存して下さい。
timestamp_col,user_id,product,quantity,amount 2025-06-01 08:00:00,u001,Apple,3,300 2025-06-01 10:15:00,u002,Banana,2,120 2025-06-02 11:30:00,u003,Cherry,5,500 2025-06-02 12:45:00,u001,Apple,1,100 2025-06-03 16:20:00,u005,Elderberry,4,800
S3バケットの構成
今回のGlue ハンズオンでは、以下のようなS3構成を使用します。
・生データ:s3://my-glue-bucket0001/raw/raw_data.csv
・加工済みデータ:s3://my-glue-bucket0001/processed/year=○○○○/month=○○/day=○○/part-0000.parquetバケットと各フォルダの概要
・バケット名:my-glue-bucket0001(一意の名前で作成する必要があるため任意の名前で作成する)
・生データ用フォルダ:/my-glue-bucket0001/raw/(作成したバケット配下にrawというフォルダを作成)
・加工済みデータ用フォルダ:/my-glue-bucket0001/processed/(Glue Jobを実行した際に、作成したバケット配下にprocessedというフォルダが自動で作成される)Glue Jobで、
processed/year=○○○○/month=○○/day=○○/が作成される流れを解説します。
・Glue Jobが、生データからtimestamp_colの2025-06-01等の年月日の情報を読み込む。
・読み込んだ年月日の情報を反映させ、processed配下にyear,month,dayのフォルダを作成する。
・最後に該当のdayフォルダ内にparquet形式で加工済みデータを保存する。
S3バケットの作成
1.AWSコンソールで「S3」サービスにアクセス
2.「バケットを作成」ボタンをクリック
3.バケット名:my-glue-bucket0001(一意な名前で任意に設定)
4.リージョン:Glueを使用するリージョン(例:ap-northeast-1 東京)を選択
5.他の設定はそのままでOK(必要に応じてバージョニングや暗号化を設定)
6.「バケットを作成」をクリックraw/ フォルダの作成
1.作成したバケットをクリック
2.「フォルダを作成」ボタンを押す
3.フォルダ名に raw と入力(末尾スラッシュ不要)
4.「フォルダを作成」をクリックprocessed/ フォルダについて
・このフォルダは手動で作成する必要はありません。
・今回はGlue Job でパーティションキーを指定しているのでJob実行時に自動でprocessedフォルダと配下のサブフォルダも作成されます。
3.1 S3にデータをアップロード
- マネジメントコンソールで「S3」にアクセス
- 環境準備で作成したバケットとキー(例:
my-glue-bucket0001/raw) を選択 - 環境準備で作成した
raw_data.csvを raw/ にアップロード
3.2 IAMポリシー・ロールの作成
- ロール作成画面から下記2つのポリシーをロールに付与する(CrawlerとJobの両方で使用)
・AWSGlueServiceRole(AWS管理ポリシー): Glueサービスが動作するために必要な基本権限を提供。
・S3へのカスタムポリシーの作成:
1. 「ポリシーを作成」をクリックし、新しいタブでポリシーを作成
2. 「JSON」タブを選択し、以下のJSONポリシーを入力します。
(my-glue-bucket0001の部分は、作成したS3バケット名に置き換える)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::my-glue-bucket0001/*"
]
}
]
}2. ロール名glue-demo-role を入力して作成
3.3 Glue Crawlerの作成・実行 (rawデータ用)
- 「AWS Glue」 → 「クローラー」 → 「クローラーの作成」
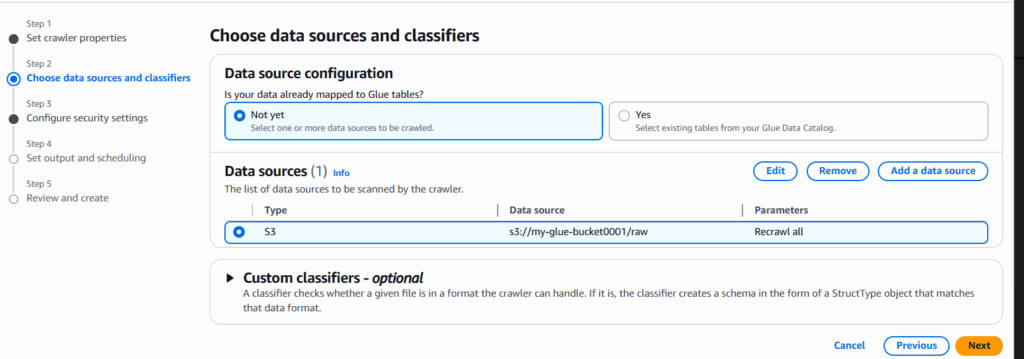
- 名前:raw-crawler(任意の名前)を入力して「次へ」
- 「データソースを追加(Add a data source)」をクリックし、S3のパス:
s3://my-glue-bucket/rawを入力し「次へ」
- IAMロール:先ほど作成した
glue-demo-roleを選択し「次へ」 - 「データベースを追加」をクリックし、
raw_databaseを作成しターゲットデータベースとして選択する
- テーブル名のプレフィックスには何も入力せずに「次へ」
(s3://my-glue-bucket/rawのパスを読み取り自動的にテーブル:「raw」が作成される) - 「クローラーを作成する」を押下
- 作成した
raw-crawlerを選択して「実行」ボタンを押下
3.4 作成されたData Catalogの確認(rawテーブル)
AWS Glue→Data Catalog→データベースを選択し、raw_databaseが存在することを確認します。- raw_database をクリックし、テーブルタブに移動します。
raw テーブルが作成され、timestamp_coluser_idなどのカラムが正しく認識されていることを確認します。
3.5 Glue Jobの作成・実行
1. 左タブから「ETLジョブ」を選択し「スクリプトエディター」を選択
2. Engine は Spark を選択し、Upload script に下記コードをraw_to_processed.py などの名前でpyファイルに保存してアップロード
import sys
from awsglue.context import GlueContext
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql.functions import to_timestamp, year, month, dayofmonth
from awsglue.dynamicframe import DynamicFrame
# --------------------------------------------------
# 1) 引数取得 & コンテキスト初期化
# --------------------------------------------------
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
# --------------------------------------------------
# 2) Data Catalog から DynamicFrame 読み込み
# --------------------------------------------------
dyf_raw = glueContext.create_dynamic_frame.from_catalog(
database="raw_database",
table_name="raw",
transformation_ctx="dyf_raw"
)
# --------------------------------------------------
# 3) DataFrame に変換 & カラム加工
# --------------------------------------------------
df = dyf_raw.toDF()
df_transformed = (
df
.withColumn("event_time", to_timestamp("timestamp_col", "yyyy-MM-dd HH:mm:ss"))
.withColumn("year", year("event_time").cast("int"))
.withColumn("month", month("event_time").cast("int"))
.withColumn("day", dayofmonth("event_time").cast("int"))
.drop("timestamp_col")
)
# --------------------------------------------------
# 4) DynamicFrame に再変換
# --------------------------------------------------
dyf_transformed = DynamicFrame.fromDF(
df_transformed, glueContext, "dyf_transformed"
)
# --------------------------------------------------
# 5) Parquet 形式でパーティション出力
# --------------------------------------------------
glueContext.write_dynamic_frame.from_options(
frame=dyf_transformed,
connection_type="s3",
connection_options={
"path": "s3://my-glue-bucket0001/processed/",
"partitionKeys": ["year", "month", "day"]
},
format="parquet",
transformation_ctx="write_parquet"
)
# スクリプト全体の流れ(まとめ)
# ①初期化: SparkとGlueのコンテキストを作成
# ②読み込み: Glue CatalogのテーブルをDynamicFrameで読み込む
# ③加工: DataFrameでデータ型変換+カラム加工+パーティションキー追加
# ④書き出し準備: DynamicFrameに戻す
# ⑤出力: Parquet形式でS3に保存+年・月・日のパーティション自動生成3. Job detailsタブを選択
4. 名前:raw-to-processed-job(任意の名前)
5. IAM Role: 作成したglue-demo-roleを選択する
6.保存ボタンを押下
7.raw-to-processed-jobを選択して、ジョブ実行ボタンを押下
3.6 Job実行後のParquetファイル出力確認
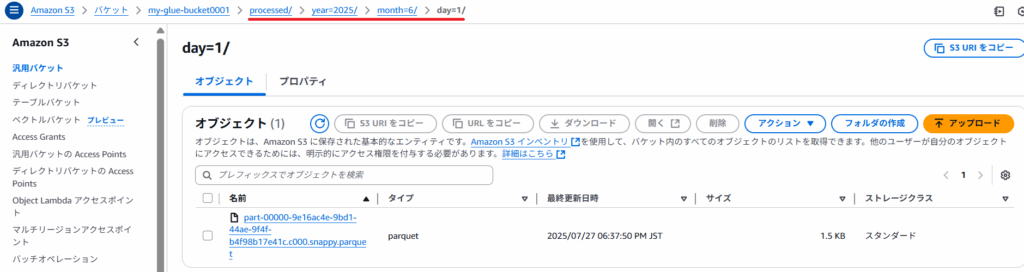
- S3へアクセス
s3://my-glue-bucket0001/processed/に移動year=2025/month=6/day=1/などのフォルダ構造が生成されているか確認part-0000∼.parquetなどのParquetファイルがあれば成功!
3.7 Glue Crawlerの作成・実行 processedデータ用
- 本記事の
3.3 Glue Crawlerの作成・実行 (rawデータ用)で作成したraw_crawlerと同じ要領(S3のパスと各名前は下記参照)でprocessed-crawlerを作成する
データベース名:processed_database
クローラー名:processed-crawler
パス:s3://my-glue-bucket0001/processed/ - 作成した
processed-crawlerを選択して「実行」ボタンを押下。
3.8 変換結果の確認 processedテーブル
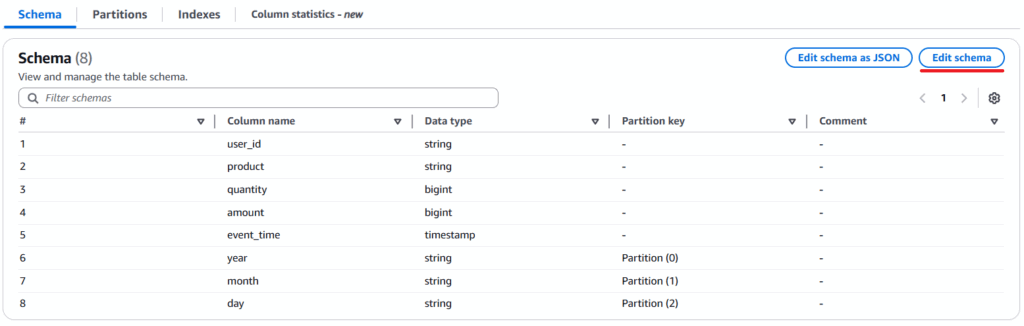
AWS Glue→Data Catalog→データベースを選択し、processed_databaseをクリックprocessedテーブルをクリックSchemaから、以下の観点を確認する。
・timestamp_colカラム(データ型:string)が削除され、event_timeカラム(データ型:timestamp)が追加されていること
・year,month,dayが追加されそれぞれのPartition keyが追加されていること
4. まとめ
本記事では、以下のハンズオンを実施しました。
・Glue Crawlerを実行しS3の生データからスキーマ情報を自動検出し、Glue Data Catalogにメタデータを集約
・Glue Jobを用いてPythonスクリプトでデータの変換(タイムスタンプの整形、パーティションキーの追加など)を行う
・最終的にParquet形式でS3にロードする一連のプロセスを実施
AWS Glueは、データレイクの構築と運用をサポートするフルマネージドサービスであり、データエンジニアリングの作業を簡素化します。
5. 最後に
最後までお読みいただきありがとうございます!
今回のハンズオンが、皆さんのデータエンジニアリング学習の第一歩となれば幸いです。
また、前編と後編を通して見て頂いた事で皆さんのGlueとETL処理の理解が深まれば幸いです!
気になる点があれば、AWSの公式ドキュメント等も活用しながら、さらに理解を深めていきましょう。
次回は、Glue StudioやGlue DataBrewを使用したETL処理について解説致します。