はじめに
後編では、ハンズオンの内容紹介後に、環境準備からAWS Glue DataBrewによるクレンジング、Glue StudioによるETLジョブの構築・実行、S3での結果確認までの詳細な手順を説明します。
Glue DataBrewとGlue Studioの概要/特徴、ならびにハンズオンの概要については前編をご覧ください。
前編はこちら:AWS Glue DataBrewとStudioを使用しノーコードでETL処理の構築【前編】
1. 概要
1.1 前編
・AWS Glue DataBrewとStudioの概要と・特徴について解説
・ハンズオンの概要について解説
1.2 後編
・ハンズオンの内容紹介
・環境準備からAWS Glue DataBrewによるクレンジング、Glue StudioによるETLジョブの構築・実行、S3での結果確認までの詳細手順の解説
2. ハンズオン内容紹介
2.1 目的とゴール
目的
- DataBrewとStudioの役割の理解
- DataBrewがデータクレンジング・品質チェックに特化していること
- StudioがETLパイプライン構築に特化していること
- 両者を組み合わせることで効率的なデータ処理が実現できること
- ノーコード・ローコードツールの基本的な操作習得
- コーディング不要でデータ処理を実施
- GUIベースの直感的な操作を実践
- 欠損値処理やデータ型変換といった基本的なクレンジング処理を実践
ゴール
- DataBrewで生データの品質問題を修正できる
- データプロファイリング機能を使用してデータ品質を可視化
- 欠損値や異常値を適切に処理するレシピを作成
- クレンジングジョブを実行してデータを整形
- StudioでビジュアルにETLパイプラインを構築できる
- ドラッグ&ドロップでノードを配置・接続
- データ変換処理(Change Schema、Filter)を設定
- パーティション分割されたParquet形式でのデータ出力
本ハンズオンで実施しないこと
本ハンズオンは、DataBrewとStudioの基本操作と使い分けを理解することに焦点を当てています。
そのため、以下のような高度な処理や複雑なシナリオは扱いません。
- 複数データソースの結合(Join処理): 単一データセットの処理に限定
- 複雑な集計処理(Aggregate): シンプルなフィルタリングのみを実施
- 高度なデータ品質ルール: 基本的な欠損値処理・データ型変換のみ
- カスタムPySparkコードの記述: ビジュアルツールの標準機能のみを使用
2.2 実施する処理の概要
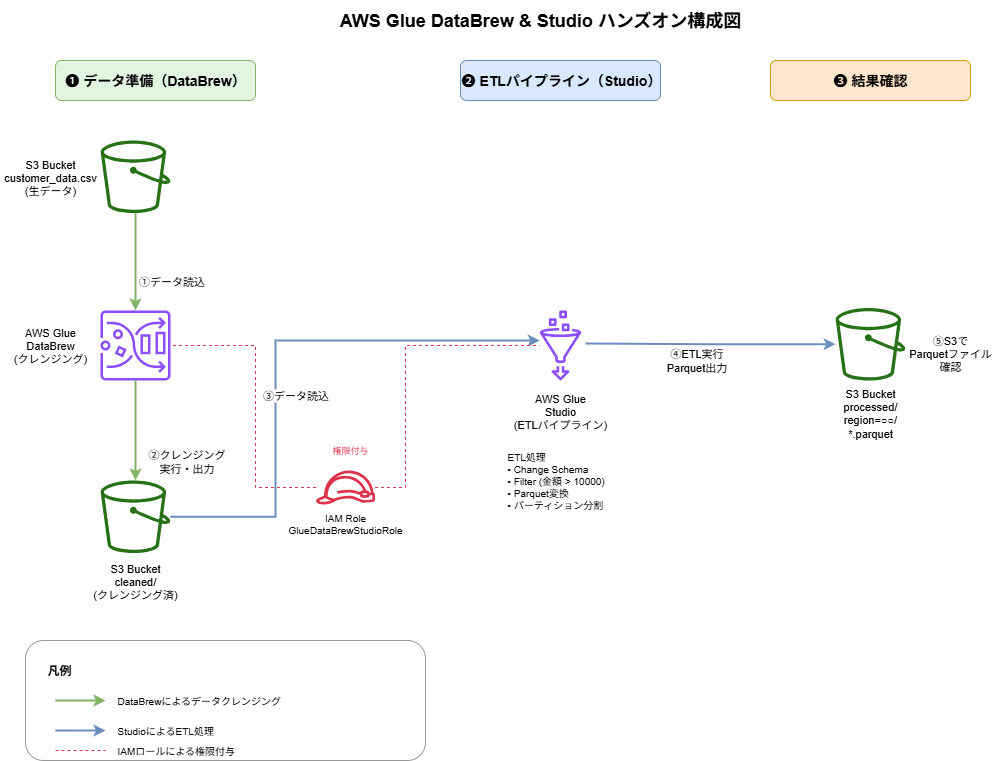
本ハンズオンで扱うデータと具体的な処理内容は以下の通りです。
使用するデータ
顧客の購入履歴データ(CSV形式)
- カラム: customer_id, name, email, age, purchase_amount, purchase_date, region
- データ件数: 5件
- データ品質の問題: email列に欠損値が存在
DataBrewで実施するデータクレンジング
- 欠損値の処理: email列の空白値を
no-email@unknown.comで補完 - 理由: 後続の処理でメール配信機能を想定し、欠損値を識別可能な値に置き換える
Studioで実施するETL処理
- データ型変換(Change Schema)
customer_id: string型に変換age: int型に変換purchase_amount: double型に変換- 理由: 分析用途に適したデータ型に統一
- 高額購入顧客の抽出(Filter)
- 条件:
purchase_amount > 10000 - 理由: ターゲット顧客を絞り込む
- 地域別パーティション分割(Data Target)
- パーティションキー:
region列 - 出力形式: Parquet(Snappy圧縮)
- 理由: 地域別の分析を効率化し、クエリパフォーマンスを向上
2.3 手順の流れ
本ハンズオンは、以下の手順で進めます。詳細な手順は次の章で解説します。
- 環境準備
- S3バケットの作成とサンプルデータのアップロード
- DataBrewとStudio実行用のIAMロール作成
- DataBrewでデータクレンジング
- プロジェクトを作成し、データの品質問題を自動検出
- GUIでクレンジングレシピを作成・実行
- StudioでETLパイプライン構築
- ビジュアルエディタでETLワークフローを設計
- ドラッグ&ドロップでデータ変換処理を定義
- Jobの実行(ETL処理)
- 結果確認
- S3での処理済みデータ確認
3. ハンズオン詳細手順
ここから実際にハンズオンを実施する為の詳細な手順を解説します。
3.1 環境準備
3.1.1 S3バケットとデータの準備
- S3コンソールで「バケットを作成」
- バケット名:
glue-databrew-demo-bucket(一意な名前で設定) - 以下のCSVデータを
customer_data.csvとして保存し、バケットにアップロード
customer_id,name,email,age,purchase_amount,purchase_date,region 001,田中太郎,tanaka@example.com,35,15000,2025-01-15,東京 002,佐藤花子,sato@example.com,28,25000,2025-01-16,大阪 003,山田次郎,yamada@example.com,42,8000,2025-01-17,名古屋 004,鈴木美咲,,29,18000,2025-01-18,福岡 005,高橋雄一,takahashi@example.com,35,32000,2025-01-19,東京
- Glue Databrewレシピの実行後のデータを格納する
cleaned/フォルダを作成 - Glue Studio でジョブ実行後のデータを格納する
processed/フォルダを作成
3.1.2 IAMロールの作成
- IAMコンソールで「ロール」→「ロールを作成」
- 信頼されたエンティティを下記のJSONに書き換える
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"glue.amazonaws.com",
"databrew.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}- ポリシーをアタッチ:
AWSGlueDataBrewServiceRoleAWSGlueServiceRoleAmazonS3FullAccess - ロール名:
GlueDataBrewStudioRoleを入力する - 「ロールを作成」をクリック
3.2 DataBrewでデータクレンジング
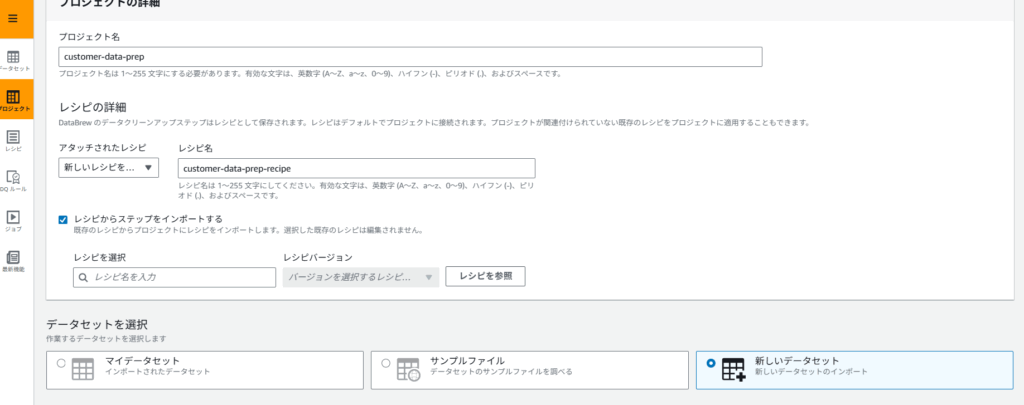
3.2.1 プロジェクトの作成
- 検索窓から AWS Glue DataBrew → 左タブから「プロジェクト」→「プロジェクトを作成」
- 「データセットを選択」から「新しいデータセット」を選択
- 設定値:
- プロジェクト名:
customer-data-prep - レシピ名:
customer-data-prep-recipe - データセット名:
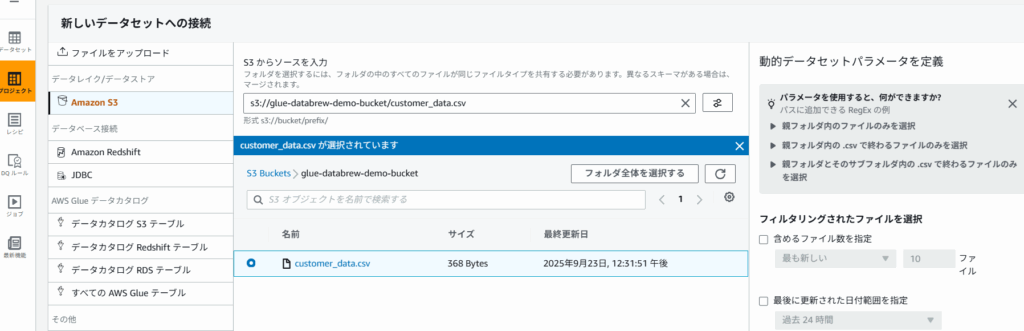
customer_data - データソース:
s3://glue-databrew-demo-bucket/customer_data.csv - IAMロール:
GlueDataBrewStudioRole
- プロジェクト名:
- データクレンジングの(欠損値の処理)実施
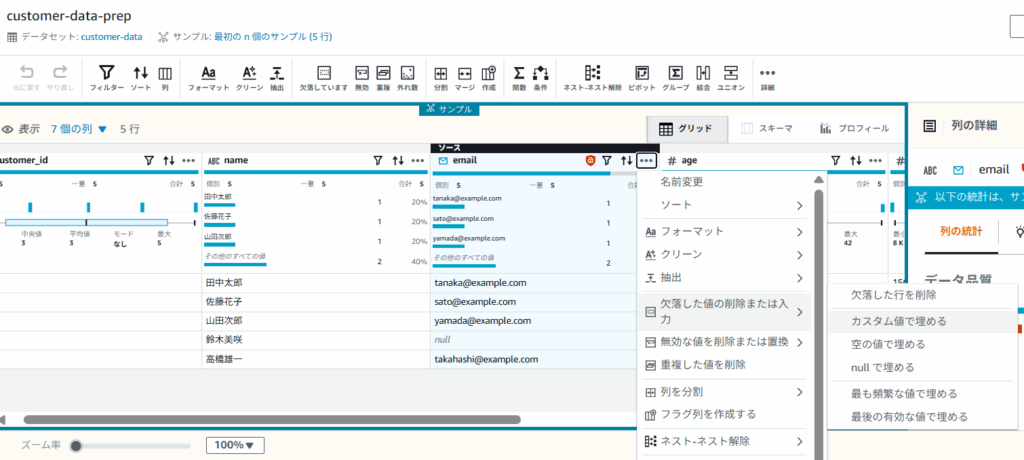
- null値が存在する
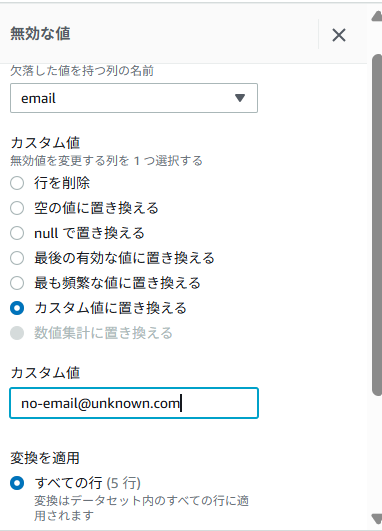
email列をクリック - ・・・(列アクション)から「欠損した値の削除または入力」→「カスタム値で埋める」を選択
- カスタム値の入力欄から
no-email@unknown.comを入力 - 「適用」ボタンをクリック
email列の該当のセルにno-email@unknown.comが存在することを確認する
- null値が存在する
3.2.2 レシピの実行
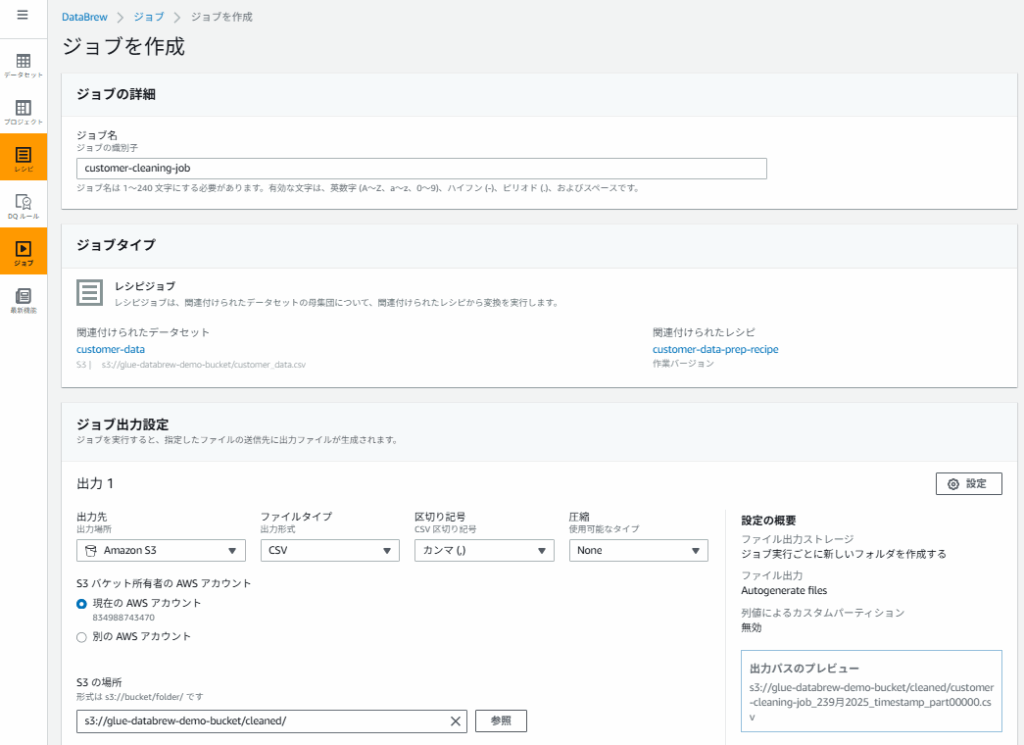
- プロジェクト画面から先程作成した「customer-data-prep」を選択し「ジョブを実行」をクリック
- ジョブ名:
customer-cleaning-job - 出力先:s3://glue-databrew-demo-bucket/cleaned/
- 出力形式:CSV
- IAMロール:
GlueDataBrewStudioRole - 「ジョブを作成し実行」ボタンをクリック
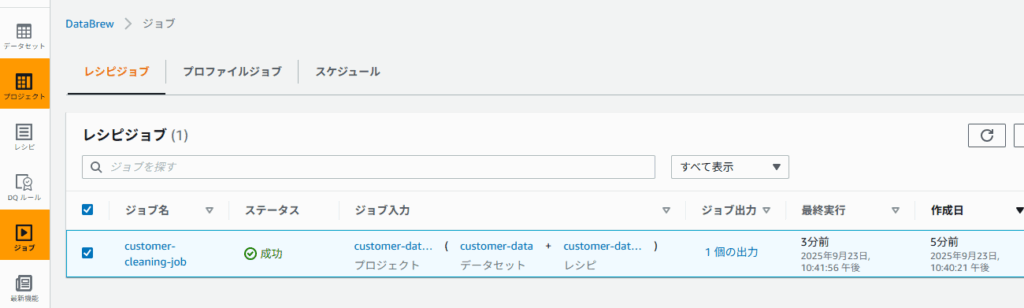
- 左タブの「ジョブ」を選択し
customer-cleaning-jobが成功している事を確認 - s3://glue-databrew-demo-bucket/cleaned/ 配下にCSVファイルが作成されていることを確認
3.3 StudioでETLパイプライン構築
3.3.1 ビジュアルETLジョブの作成
- 検索窓から Glue Studioと入力しクリック →「ビジュアル ETL」を選択
- タブの
visualを選択した状態でAdd nodesをクリック - Data Source ノード:
- 検索窓から
S3と検索し、sourceと表示されているS3をクリック Data source S3 bucketから下記の通り2つの項目を設定- S3 URL:s3://glue-databrew-demo-bucket/cleaned/
- Data format:CSV
- 検索窓から

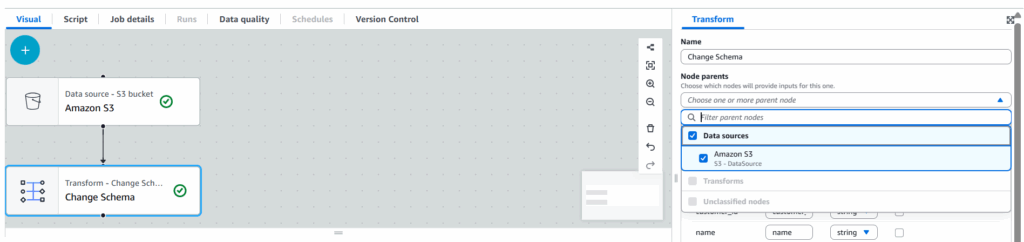
- ApplyMapping ノード:
- 検索窓から
Change Schemaをクリック - Node parentsからData Source ノードのS3をクリック
- Change Schema (Apply mapping)からデータ型変換を設定:
customer_id: stringage: intpurchase_amount: double
- 検索窓から
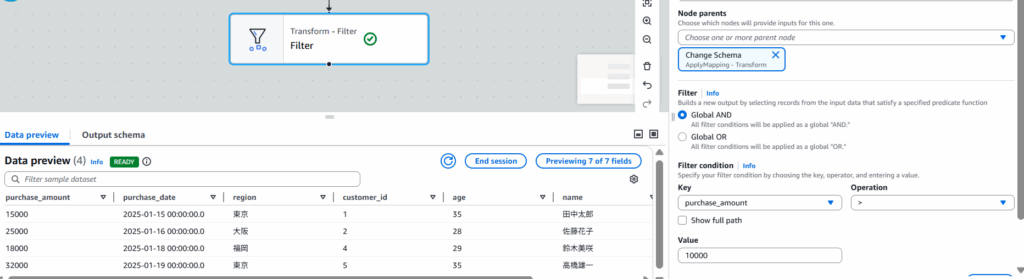
- Filter ノード:
- 検索窓から
Filterをクリック - Node parentsから
Change Schemaをクリック - 条件:
purchase_amount > 10000(高額購入顧客に絞り込み)
keyにpurchase_amountを選択し、Operationに > を選択
- 検索窓から
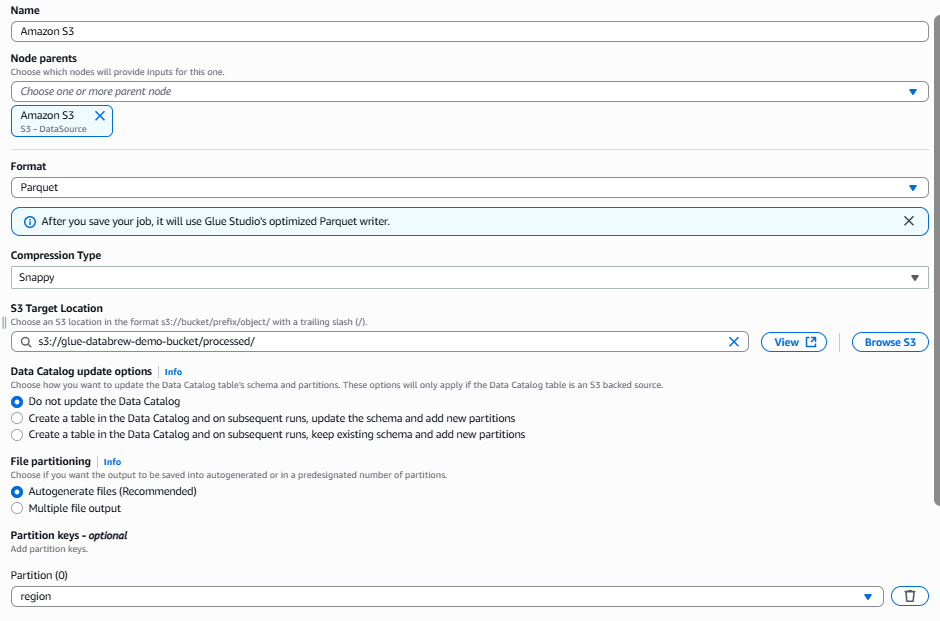
- Data Target ノード:
- 検索窓から
S3と検索し、targetと表示されているS3をクリック Data target S3 bucketから下記の通り4つの項目を設定- Node parents:S3 – DataSource
- S3ターゲットパス:
s3://glue-databrew-demo-bucket/processed/ - Format:Parquet
- Compression Type: Snappy
- パーティション:
region列
- 検索窓から
3.3.2 ジョブの実行
- 「Job details」で設定:
- 名前:
customer-etl-job - IAMロール:作成済みの
GlueDataBrewStudioRoleを選択する - その他の項目はデフォルトのままの設定
- 「保存」→「実行」でジョブ開始
3.4 結果確認
3.4.1 出力データの確認
- S3コンソールで
processed/フォルダを確認 - リージョンごとにパーティション分割されたParquetファイルが生成されていることを確認
※purchase_amount > 10000のフィルタ条件により、名古屋のデータ(8000円)は除外されています
4. まとめ
最後までご覧いただきありがとうございます!
AWS Glue DataBrewとStudioを使用してノーコード・ローコードでのETL処理を解説しました。
これらのツールを組み合わせることで、コーディングスキルがなくても効率的なデータ処理パイプラインを構築できます。
不明点や他に気になる点があればAWS公式サイトも確認してみてください。
前回の記事ではGlue Jobを使用したETL処理についても解説していますので気になる方は是非ご覧ください。