この記事ではAWSのBIサービスであるQuickSightの概要、QuickSightを用いた実測データの可視化手法、及び予測機能を用いた実測データと予測データの比較結果を紹介していきたいと思います。
はじめに ~データ分析の流れ~
まずは、データ分析を進めるにあたりそのステップを説明し、この中でQuickSightの位置づけを明確にしたいと思います。
データ分析を進める際、まずは統計的手法を用いる・分析用のプログラムを組むといったアクションを行うと、分析すること自体が目的となってしまい、本来ゴールとなる経営判断のための意思決定まで到達できない恐れがございます。
結果がよい分析をしようとするあまり、意図せずに都合のよいデータ(想定通りとなることが予想される標本データ)ばかりを集めてしまい、想定通りの結果を生み出す動きをしてしまうかもしれません。あくまで一例ですが、こういった罠に陥らないようにするためにも、データ分析は一般的に下記プロセスで進め、目的を見失わずにゴールまで進める必要がございます。
- 分析目的設定
- 現状把握・課題把握・課題定義
- 要件定義、設計方針固め
- データ収集
- データ格納、変換(前処理)
- データ集計、予測
- レポーティング、意思決定
最終的には、データ分析を行うことで経営判断に用いるための情報収集・意思決定の判断材料を提供することがゴールとなります。
このプロセスにおけるNo.5, 6を実施するにあたり、データを集計・可視化し、将来的な予測や経営戦略上の洞察を得るためにBI(Business Intelligence)ツールを用います。
上記のプロセスを進めるにあたり、データ分析サービスを提供する様々なSaaSがありますが、AWSでは下記カテゴリ毎に分けたサービスが提供されています。

[AWS での分析](https://aws.amazon.com/jp/big-data/datalakes-and-analytics/?nc=sn&loc=0)
上記カテゴリのビジネスインテリジェンスがBIツールを指し、それがQuickSightとなります。
BIツール ~Quicksight紹介~
QuickSightは、手軽に分析環境を構築できるフルマネージド型のBIツールとなります。
ブラウザもしくはモバイルApp経由で、ダッシュボード上に作成した様々な取得データ群にアクセスし、ドラッグ&ドロップの直感的な操作で分析のための情報を得ることができます。
加えて、機械学習(ML)を利用したデータ予測も行うことができます。
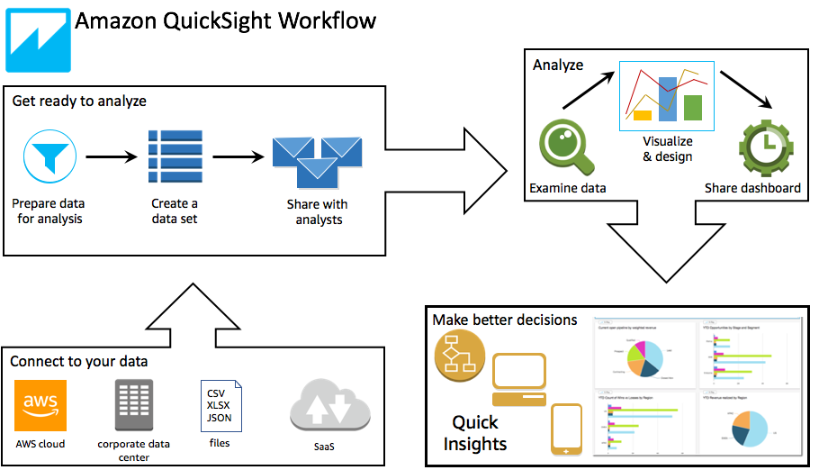
Quicksightでサポートされているデータソース(データの情報源)はS3やRedshiftといったAWS環境内のデータの他に、Google BigQuery・Snowflakeといった非AWSが扱う構造化データもサポートしています。
サポート対象のデータソースについて、詳しくは右記AWS公式ページを参照ください。サポートされているデータソース
料金形態は大きく2種類あり、①ユーザ毎の料金、②キャパシティ料金、があります。
下記は記事作成時点の費用となります。1$=150円換算
①ユーザ毎の料金
この費用モデルでは、契約する各ユーザタイプとその利用数により料金が計上されます。
| ユーザタイプ① | ユーザ種別 | 料金 |
| Author(作成者) | Author | 1ユーザあたり¥3,600/月 |
| Author Pro | 1ユーザあたり¥7,500/月 ※ |
| ユーザタイプ② | ユーザ種別 | 料金 |
| Reader(閲覧者) | Reader | 1ユーザあたり¥450/月 |
| Reader Pro | 1ユーザあたり¥3,000/月 ※ |
※ Amazon Q トピックを持たないアカウントにおいて、少なくとも1名のProユーザーはアカウント毎に¥37,500/月のAmazon Q有効化料金が適用されます。 [AWSの料金](https://aws.amazon.com/jp/quicksight/pricing/?nc1=h_ls]
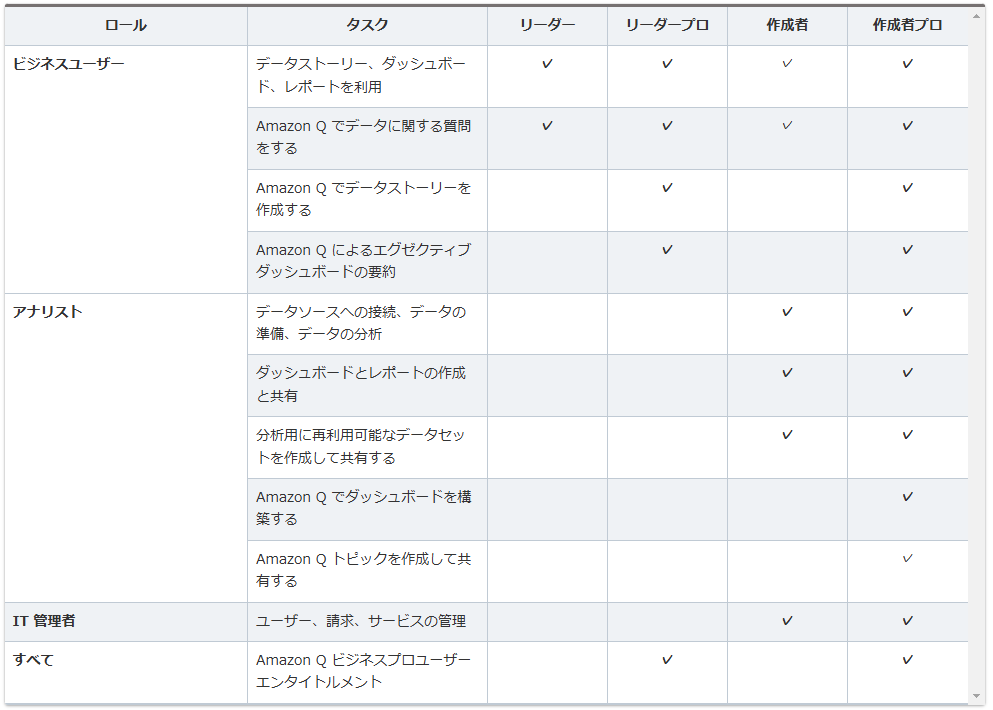
各ユーザの役割毎において選択するユーザタイプは下記となります。
②キャパシティ料金
この費用モデルでは、一定のセッション数やAmazon Qへの質問数をまとめて購入し、そのセッションを消費する形で利用します。
利用ユーザーの登録は不要であるため、継続的な利用ユーザ追加によるプロビジョニングが不要になります。
| キャパシティタイプ | 料金 |
| Reader Capacity | 500セッションあたり¥37,500~/月 |
| Amazon Q Questions Capacity | 500個の質問あたり¥37,500~/月 ※ |
Author Pro/Reader Pro/Amazon Q Questions Capacityの購入により、Amazon Qの利用が可能となります。
Amazon Qを利用し、ダッシュボード作成からサマリ作成、データに対するQAまで行うことができるようになります。
上記①②の使い分けとして、利用者は固定ユーザであるか/使用ユーザ数はどの程度か、に左右されると思います。
使用ユーザー数やアクセス頻度が多く、個別のユーザー管理が難しい場合はキャパシティプランを選択するほうが妥当となります。
また、Quicksightの機能として最終レポーティングを作成する機能、SPICE(高速なインメモリデータストア)の利用する等がありますが、こちらは別途費用が発生します。
発生費用は月間よりも年間単位の契約の方が費用削減できる等のディスカウント条件もあるため、詳しくは先に挙げたAWS公式ページを参照ください。
次項からは実際にQuicksightを用いて、オープンデータ(e-govポータル)における2015年の人口動態データの可視化、及びQuickSight標準機能である予測機能を用いて実測値と予測結果を比較したいと思います。
人口動態データは、人口動態調査人口動態統計確定数人口年次より取得できます。
BIツール ~QuickSight利用~
前処理の実施前
QuickSightよりデータ可視化を行うために、データの取込みを行います。
QuickSightへの取込み可能なデータタイプは、構造化データ/半構造化データ/非構造化データ(Amazon Q in QuickSightを使用)となります。
・構造化データ: 一般的な第三正規化されたデータであり、重複を排除した一貫性を持つデータ
・半構造化データ(json、 xml)
・非構造化データ(画像、音声等)
今回使用する対象データは構造化データとなりますが、取込む前に完全な構造化データにするための前処理が必要となります。
対象データに関しては下記3点の対応が必要です。
・表のヘッダ位置が7行目のため、不要なローを削除しヘッダ位置を1行目とするか、QuickSight側で適切なヘッダ位置が7行目と設定する必要あり。
・年次を表すカラムが欠損しており、年次が意味するカラムを表現することができないため補完する必要あり。
・年次カラム内の千と百の位が省略されているレコードが存在しており、時系列としてデータを読込ませることができないため補完する必要あり。
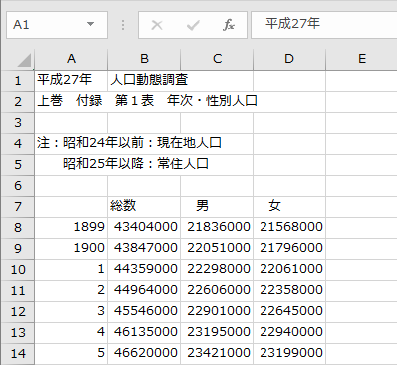
QuickSightではデータ取込み時にヘッダー位置を指定可能であるため1点目は回避できますが、それ以外の2点は修正が必要となります。
このようにデータは最初から分析目的に整形されているわけではないため、取込み前に完全なデータとなるように前処理が必要となるケースが多いです。
これはETLと言われるプロセスのT(Transform)に該当し、BIツールへの取込み(Load)に限らず、DWH(AWSで言えばRedshift)も同様です。
DWHは不完全データを取込むことができないため、事前に構造化/半構造化データの形式で完全データとして加工する必要があります。
上記の例で挙げた処理や、例えば重複データを排除する、ファイルをサポートされている形式に変換する等の処理を行います。
この前処理自体の実装は、AWSサービス内ではAWS GlueのJob、EC2インスタンスやLambda上での実装等が考えられます。
また、処理を行うプログラムとしてPythonを使用する場合は、Pandasといったライブラリを使用して手軽に変換処理を行うことができます。
上記の目的の他に、社内マーケティング部門向けといった特定のニーズに合わせて最適化されたデータであるデータマートを作成するために前処理を行うこともあります。
このデータマートを作成することによって、データの最適化、クエリの高速化、ユーザビリティ向上、といったメリットがあります。
これは事前に完全化された構造化データに対してSQLを用いてデータ加工(不要なデータ削除、複数テーブルから必要データのみ抽出等)を行い作成します。
前処理の実施後
ここからは前処理後のデータを用いてQuickSightへのデータ取込みを行います。
AWSマネジメントコンソールからQuickSightにアクセスします。
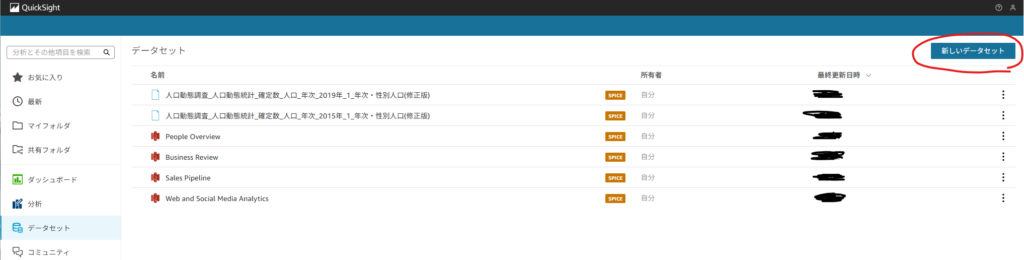
下記がデフォルトでオープンする画面となります。ここでは左カラム内の分析が選択されているため、現在取込み済みのデータが表示されています。ここではデフォルトで作成されているサンプル含め、6つの分析データが存在しています。

これより前処理後のCSVデータを取り込みます。
- 左カラムより
データセットを選択 > 左上の新しいデータセットを押下します。
- 今回は
ファイルのアップロードよりローカルから直接該当のデータをアップロードします。

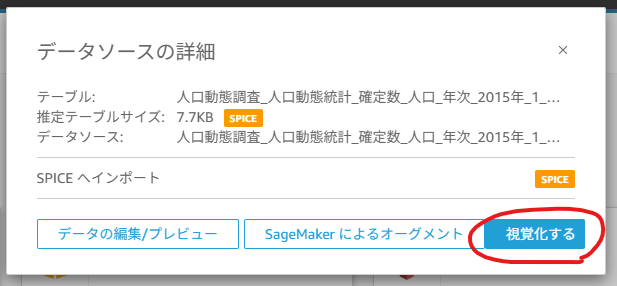
次へを押下 >視覚化するを押下し、データ取り込み完了となります。
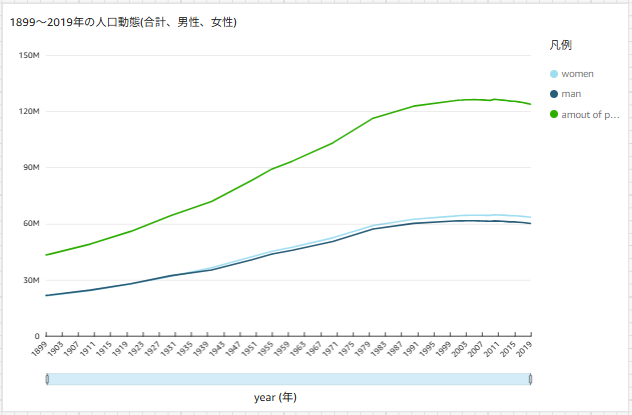
下記がデータ取込み後の折れ線グラフにて可視化した1899~2015年の人口動態となります。

上記の結果を用いて、QuickSightのデフォルト機能となる予測機能を使用し、2030年までの人口動態を表したいと思います。
この予測機能では時系列予測となるため、x軸のデータは時系列データである必要があります。
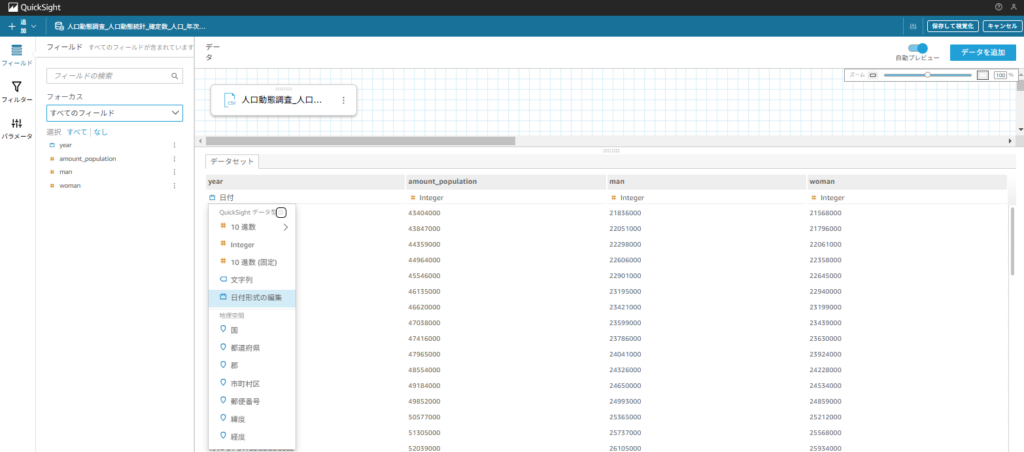
そのため、yearカラムのデータタイプが日付となっていることを確認します。ここが数値タイプintegerや文字列タイプStringでは時系列データと認識されないため、予測機能を利用することはできません。
このデータタイプは、データ取込み後でも編集できます。
データからデータセットを押下 > 対象データセットを選択し編集を押下 > 対象カラムのデータタイプで日付を押下します。
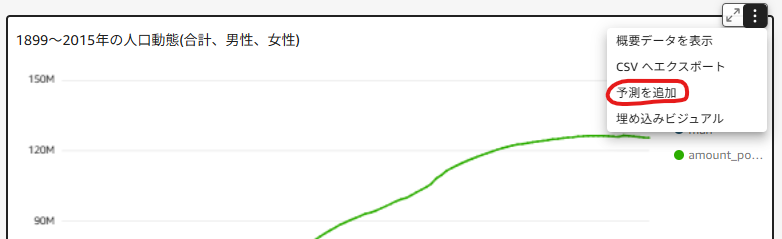
メニューオプションから予測を追加を押下します。
ここでは2030年までのデータを予測したいため、期間を進める欄を15に設定します。
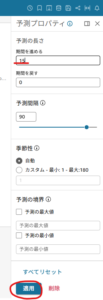
適用後、1899~2015年までのデータを基にQuickSightの予測変換機能を使用したグラフとなります。
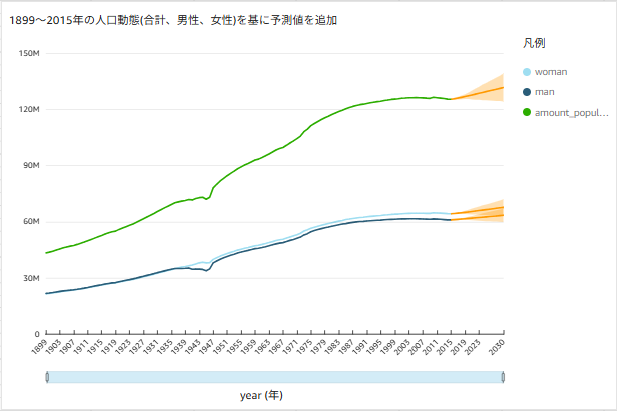
同じように、1899~2019年の人口動態をグラフ化します。
公開用のグラフが揃ったところで、右上の公開を押下し、結果をダッシュボードに追加することができます。

これで1899~2015年の実測値、1899年~2019年の実測値、1899年~2030年の予測値の3つのグラフが可視化できました。
これら実測値と予測値を比較します。
取得した予測値は下記となります。


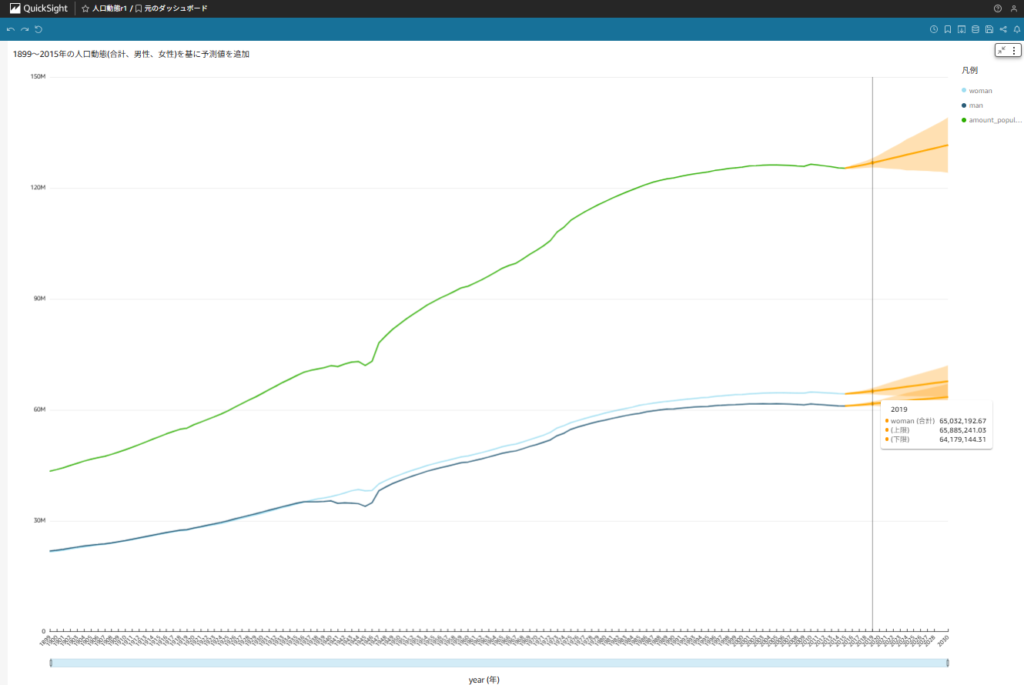
結果を比較すると、下記表のように相対誤差2%となり、数百万人単位での乖離が生じる結果となりました。
| カテゴリ | 予測値(人) | 実績値(人) | 絶対誤差(人) | 相対誤差(%) |
| 合計 | 126,786,495 | 123,731,176 | 3,055,319 | 2 |
| 男性 | 61,645,453 | 60,208,034 | 1,437,419 | 2 |
| 女性 | 65,032,192 | 63,523,142 | 1,509,050 | 2 |
これは単純な時系列予測を行っただけの簡易的な予測結果であり、他に相関する事象要因(出生率等の推移)を含めていないため乖離を生じることは予想しておりましたが、結果として百万人単位での乖離が生じることとなりました。
更に精度を高める・他の相関する要因を含めて予測精度を高めたい場合は、Amazon SageMakerといった機械学習サービスを用いて学習モデルの開発とそのトレーニングが必要となります。(Amazon QuickSight で使用される機械学習アルゴリズムについて)
最後に
実際の現場ではデータの予測結果を一度得ても、精度や確からしさを向上させるために、更に追加データ収集/前処理/分析といったサイクルを繰り返し行う必要があります。機械学習モデルを使用している場合であれば、モデルにデータを学習させ精度を高めるといったアクションが必要となります。
今回の例ではレポーティングや意思決定を伴うものではありませんが、最終的に分析結果をレポーティングし経営施策が打てるようなビジネス上の洞察を提供するためのツールとして、QuickSightのようなBIツール導入が検討に含められるのではないでしょうか。
以上、AWSのBIツールであるQuicksightの概要と簡単なサンプルを用いたデータ可視化とその予測機能を紹介しました。
概要紹介がメインとなりましたが、実装/機能面は次回以降で掘り下げて説明していきたいと思います。